
The Ideological Storm
Part 3 of a 6 Part Series on Defining Open with Thoughtfulness in the Age of AI

This is the third post in a series based directly on my keynote at the EBSCO User Group Meeting in Omaha, Nebraska, where I’m exploring what it means to reclaim information sovereignty by defining “open” through the lens of AI. Just as I did for my WOLFcon Plenary and iPres Keynote, I want to bring the substance of that talk into written form so that the conversation can continue -- and also, I had to cut a TON of content from the talk that I think is very relevant to the conversation as a whole. You can explore the rest of the series here:
Part 2: The Forcing Function
Part 3: The Ideological Storm
Part 4: A Shared Reality
Part 5: Governance and the Commons
Part 6: Reclaiming our Seat at the Table
Back in part 1 of this series, I mentioned that I wasn’t thrilled with AI, which is one of the reasons I questioned my friend Bohyun, who was an early evangelist for cultural heritage organizations.

One reason I distanced myself from AI was that the field’s prominent voices often promoted deeply disturbing ideologies. Many of their theories were rooted in Eugenics, and they held beliefs I find fundamentally reprehensible.
To give you an idea, I was already familiar with figures like Peter Thiel, a man often characterized by his techno-utopianism and a clear skepticism toward democratic ideals. My wariness extended to Elon Musk as well; initially, it was his proximity to Thiel that gave me pause, but as I dug deeper into his role at the helm of Tesla and SpaceX, his underlying moral compass became increasingly questionable to me. I had also caught the growing unrest surrounding Nick Bostrom, whose listserv correspondence revealed deeply problematic perspectives and ideas about genetic engineering, which, to me, felt like a new version of some of the ideas put forward by traditional eugenicists. It became impossible to ignore that the tycoons leading today’s major AI “Frontier Labs” (e.g., Altman, Amodei, etc.) were inextricably linked to these same individuals, and so I remain extremely skeptical.
Did something I said spark an idea?
And then I stumbled across an Instagram reel—ironic, I know—that mentioned the TESCREAL bundle. A quick search led me to Dr. Timnit Gebru and Dr. Émile Torres. Their research, published in exposes the beliefs behind today’s technology-driven future.
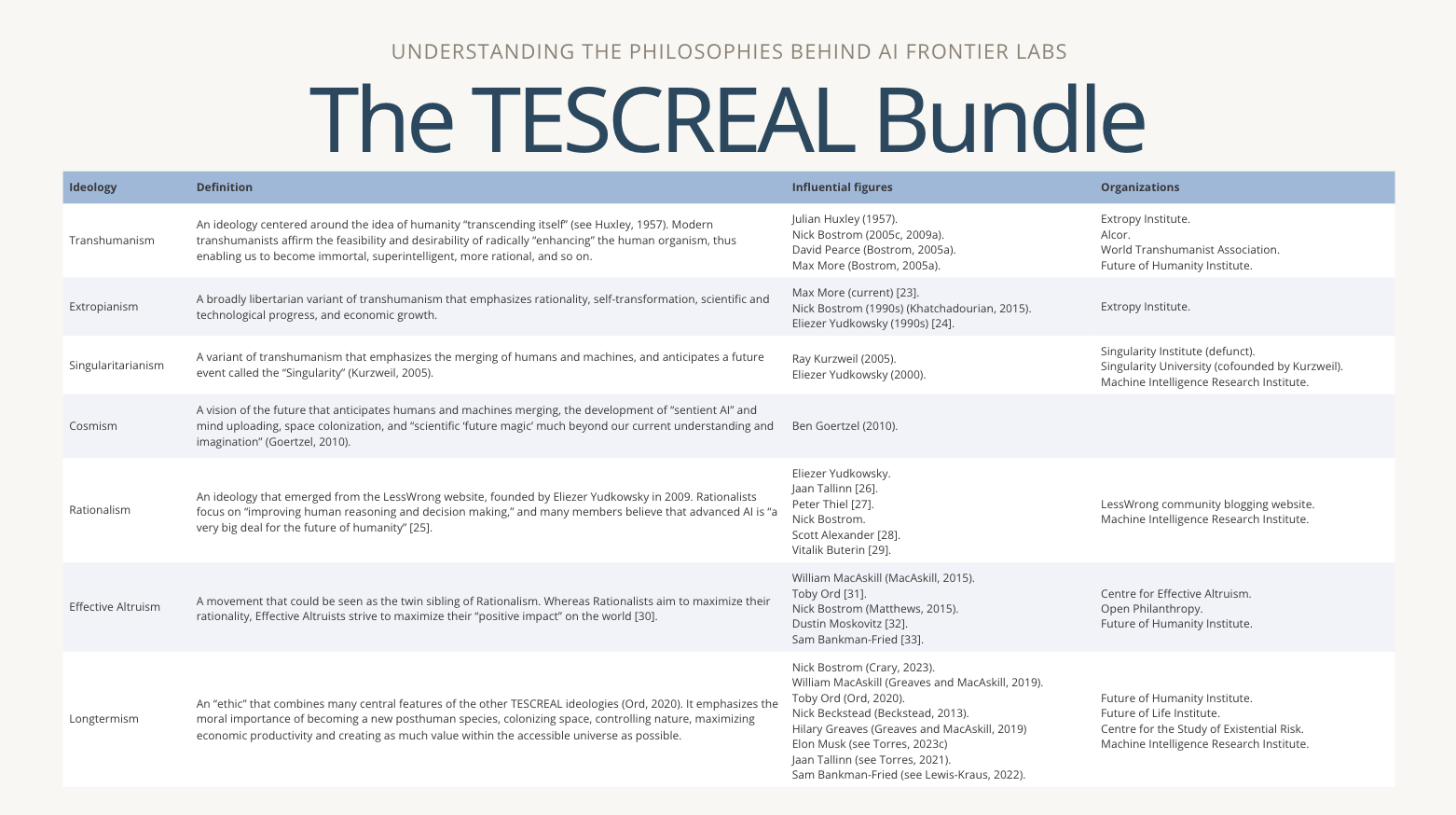
If you don’t know, TESCREAL stands for: Transhumanism, Extropianism, Singularitarianism, Cosmism, Rationalism, Effective Altruism, and Longtermism. The philosophies are often rooted in eugenics and techno-utopianism. And I want to be clear, not all TESCREALists know about the origins of their beliefs.

When I learned about the concept of the TESCREAL bundle of ideologies, it seemed par for the course for folks in Silicon Valley. It essentially represents a worldview where technology is meant to replace the human experience rather than enhance it. In that world, we aren’t people with stories and values; we are just data points waiting to be uploaded, optimized, or replaced.
However, it’s important to remember that AI is not some sentient being; it is a mirror of its architects. Once I looked past the deeply disturbing ideologies of prominent voices and focused on the technical foundations, I was able to see that these models are nothing more than math and statistics, but more importantly, they are inherently susceptible to the biases and values embedded in the data they consume—and given the current state of the internet, that is hardly a comforting thought. These systems operate through a mechanical process called Tokenization.
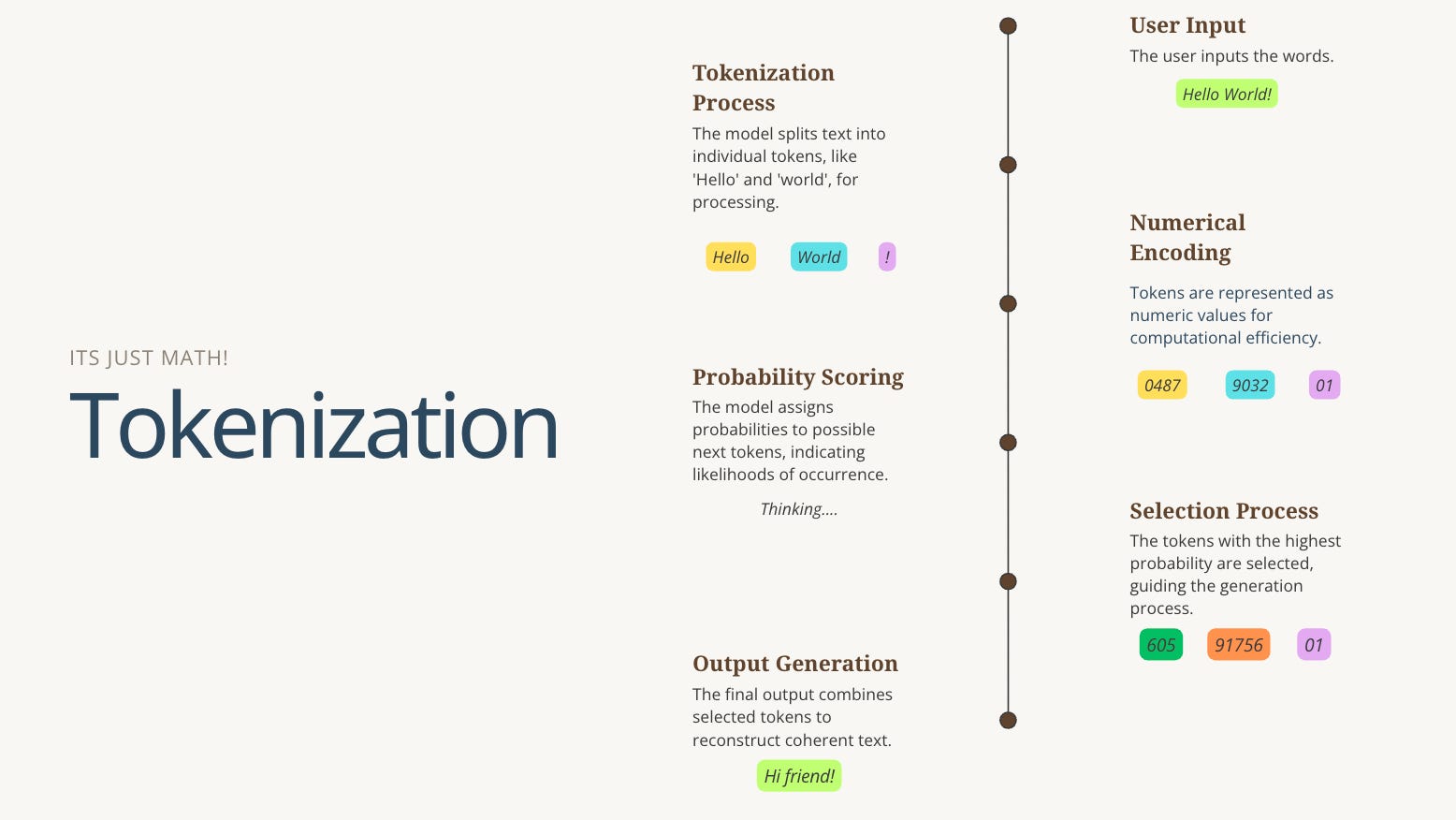
Imagine every word, or even a fragment of a word, being assigned a numerical value—a “token.” In its simplest terms, tokenization is the method of decomposing human language into smaller, bite-sized components so that an AI model can ingest it. Because these models are essentially colossal mathematical engines, they possess no capacity to “read” words; they only compute numbers. Tokenization serves as the bridge between our human expression and their binary reality.
A token can represent a complete word, a lone character, or a “subword” chunk. For instance, while a familiar word like “apple” might exist as a single token, a more intricate term like “tokenization” is often broken down into fragments such as “token,” “iza,” and “tion.” Each fragment is granted a unique ID number. When you input a prompt, the system translates your text into a sequence of these identifiers, performs its mathematical heavy lifting, and then renders those numbers as human-readable text on your screen.
When you engage with an AI, it isn’t “thinking” in any human sense. It is merely scanning a sequence of numbers and calculating the statistical probability of the next number based on the billions of examples it has ingested. It isn’t magic; it is a sequence. Once we demystify this process, we reclaim the agency to audit these tools for bias, shape their governance, and deploy them to defend the scholarly values we have stewarded for generations. The pressing question we must face is: where do the billions of documents required to fuel a statistical engine like this actually come from? AI’s relentless hunger for data is what defines the next chapter of our story.
I’ve been vocal on my Substack and in various talks about the predatory nature of AI bots and their voracious appetite for content to fuel their models, but I’m not going to assume you’ve read all of that (see below, though, if you want to).
Bots, Barriers, and the Future of the Open Web

In a recent comment on my LinkedIn newsletter, Eric Hellman proposed a somber title for his next blog post: RIP Open Access. I’d go one step further and suggest we may be inching toward RIP Open Internet. The fabric of the open web, once seen as a bastion of free information exchange, is fraying under the weight of bot traffic, legal ambiguity, and infr…
So quickly, these companies operate under the delusion that if they simply scale the amount of data they train on, they can reach the holy grail: Artificial General Intelligence (AGI). So they either send out web-scraping bots to crawl sites and capture all the data, or they rely on the Common Crawl dataset to train their models and employ content moderation and data-labeling firms to scrub and refine the datasets they use for training.
But there is a shortcut that allows them to bypass content moderation and data labeling firms entirely: us. Libraries have been the original data labelers for centuries. We are the curators and collectors of the human record. They can effortlessly crawl our repositories and use our work to curate and describe content to train their systems. And the most unsettling question remains: what happens when even that well runs dry?
More recently, they have pivoted toward the content we haven’t yet digitized. In this screenshot, you can see an invitation I received from Google, asking Emory to join the Google Books project. What’s missing from this frame is the inquiry a colleague received from Meta, specifically, a request for materials within our Special Collections. They are acutely aware that high-quality, curated content still exists beyond the reach of their current crawlers, and they know there is no repository more qualified than a library to provide it.

While we in the cultural heritage sector have long maintained a bright line between archival and non-archival materials, research data and scholarly articles, these entities do not care about such fine-grained distinctions; they only see content. The moment we lose the ability to steward and control the intellectual output and therefore the digital sovereignty of content creators, we enable a deeper, more profound corruption: the erosion of the shared reality we depend on.
My deepest concern is, what happens when they have all of that data we make publicly accessible? We already know many of these companies are finding new ways of mining data from users of their platforms. Just last week, I read that Meta said it would track employees’ screens, mouse movements, and keystrokes and use the data to train AI.
But what happens when that data isn’t enough? Will companies start targeting the data we hold behind lock and key? Will they want the administrative and restricted data that could further refine their models? Will they begin hammering at those systems next? What will we need to do to protect ourselves and the data we are legally required to protect (and in case you were wondering, yes, I did write that paragraph BEFORE the Canvas data breach)?
Next week we’ll start to talk about philosophy and how important it is to understand the why behind the cultural heritage ecosystem. In the meantime…